
2024美国大学生数学建模竞赛已经开始,如何评价2024美赛E题?
当大家面临着复杂的数学建模问题时,你是否曾经感到茫然无措?作为2022年美国大学生数学建模比赛的O奖得主,我为大家提供了一套优秀的解题思路,让你轻松应对各种难题。
让我们来看看美赛的E题!CS数模团队高质量筹划讨论,使用最前沿的算法和丰富的可视化方法来解决了E题,运用深度神经网络解决房屋保险可持续性与历史建筑多标签分类问题,涵盖模型设计、训练、评估、预测与可视化。同时,运用SVM回归探讨极端天气事件影响,包括模型构建、训练、预测与视觉呈现。已经更新!
问题重述
问题 E:财产保险的可持续性
2024年ICM提出的问题涉及财产保险行业在面临不断增多的极端天气事件,特别是由气候变化引起的情况下的可持续性。文档指出,财产所有者和保险公司正面临严重危机,全球在近年内已经经历了超过1000次极端天气事件,导致超过1万亿美元的损失。2022年,自然灾害的保险索赔较30年平均水平增加了115%。由于洪水、飓风、气旋、干旱和森林火灾等严重天气事件的损失预计将增加,保险费用迅速上涨,预计到2040年将上涨30-60%。
不仅财产保险费用不断上涨,而且越来越难找到,因为保险公司改变了愿意承保政策的方式和地点。导致保险费用上涨的与天气有关的事件在世界各地看起来都不同。此外,全球保险保护缺口平均达到57%,且仍在增加。这突显了该行业面临的两难境地 - 对保险公司而言,是盈利能力的新兴危机,对财产所有者而言,是负担能力的问题。
COMAP的保险灾害建模员(ICM)关注财产保险行业的可持续性。随着气候变化增加了更严重的天气和自然灾害的可能性,ICM希望确定如何最好地布局财产保险,以便系统在覆盖未来索赔的同时,确保保险公司的长期健康。如果保险公司在太多情况下都不愿意承保,由于顾客太少而可能破产。相反,如果他们承保了过于冒险的政策,可能会支付过多索赔。保险公司应在何种条件下承保政策?他们何时选择承担风险?财产所有者能否影响这一决策?开发一个模型,供保险公司确定是否在极端天气事件不断增多的地区承保政策,并使用两个在不同大陆上经历极端天气事件的地区演示您的模型。
展望未来,社区和房地产开发商需要思考如何在何处进行建设和增长。随着保险格局的变化,必须做出未来房地产决策,以确保财产更具韧性并经过精心建设,包括提供适当服务给不断增长的社区和人口。您的保险模型如何适应评估在特定地点、如何以及是否建设的地方?
您的保险模型可能会建议不在某些社区承保当前或未来的财产保险政策。这可能导致社区领导者面临有关具有文化或社区重要性的建筑物的艰难决策。例如,北卡罗来纳州外滩的海特拉斯灯塔被搬移,以保护这座历史悠久的灯塔及其周围的旅游业。作为社区领导者,您如何确定社区中应该保存和保护的建筑物,因为它们具有文化、历史、经济或社区重要性?为社区领导者制定一个保存模型,以确定他们应采取的措施程度,以保护社区中的建筑物。
选择一个历史地标 - 不是海特拉斯灯塔 - 位于经历极端天气事件的地方。运用您的保险和保存模型,评估这一地标的价值。根据您从解决方案结果中获得的见解,给社区写一封一页的信,建议该地标的未来计划、时间表和费用提案。
您的PDF解决方案不得超过25页,其中包括:
• 描述问题和分析结论的一页摘要。
• 目录。
• 您的完整解决方案。
• 一封社区信。
• AI使用报告(如果使用)
问题整合后如下:
1. 财产保险行业可持续性问题: 如何确保财产保险行业在气候变化引发的极端天气事件增多的背景下具有可持续性,覆盖未来索赔成本,同时保障保险公司的盈利和长期健康。
2. 承保政策决策问题: 保险公司在何种条件下应该承保财产保险政策?如何建立系统韧性以覆盖未来索赔成本,同时确保盈利能力?
3. 社区建设和保护问题:如何调整保险模型,以评估在何处、如何以及是否在某些地方进行建设,以适应不断变化的保险背景?社区领导者在决定是否保留建筑物时如何考虑文化、历史、经济或社区重要性?
4.建筑物保护模型问题 为社区领导者开发一个模型,以确定应采取何种措施来保护具有文化、历史、经济或社区重要性的建筑物。
5. 方案呈现问题: 如何将解决方案以PDF形式呈现,包括摘要、目录、完整解决方案、社区信以及使用AI工具的AI使用报告?
6. 文档引用的主要挑战: 对于保险行业来说,是盈利能力和对财产所有者来说是负担能力的问题,以及社区领导者面临的决策挑战,如何保护具有文化或社区重要性的建筑物。
开发一个模型,供保险公司确定是否在极端天气事件不断增多的地区承保政策,并使用两个在不同大陆上经历极端天气事件的地区演示您的模型。
我们这里采用支持向量机进行决策与分析。支持向量机(SVM)的基本思想是通过找到一个最优的超平面来将不同类别的样本分开,使得两类样本之间的间隔最大化。对于问题一,我们可以考虑使用SVM来建立一个分类模型,将不同地区的风险水平分为不同的类别,以评估财产保险的可持续性。以下是结合公式的SVM建模思路:
1. SVM分类问题的基本公式:
对于线性SVM,其分类问题的基本公式为:

其中:
- f(x) 是样本 x 的分类结果,取值为 +1 或 -1。
-  是法向量(法向量是超平面的法向量),决定了超平面的方向。
是法向量(法向量是超平面的法向量),决定了超平面的方向。
-  是输入样本的特征向量。
是输入样本的特征向量。
- b 是偏置项,表示超平面与原点的距离。
2. 软间隔SVM:
在处理非线性可分的情况下,引入松弛变量  来允许一些样本出现在超平面的错误一侧。软间隔SVM的目标函数为:
来允许一些样本出现在超平面的错误一侧。软间隔SVM的目标函数为:

其中:
-  是超平面的法向量的范数。
是超平面的法向量的范数。
- C 是惩罚参数,控制了分类错误的惩罚程度。
-  是松弛变量,表示第 i 个样本允许的错误程度。
是松弛变量,表示第 i 个样本允许的错误程度。
3. 非线性SVM:
对于非线性问题,可以引入核函数来将输入样本映射到高维空间,通过在高维空间中找到一个线性超平面来解决非线性问题。常用的核函数包括径向基函数(RBF)核:

其中:
-  是样本
是样本  在高维空间的内积。
在高维空间的内积。
-  是核函数的宽度参数。
是核函数的宽度参数。
通过解上述优化问题,得到最优的  ,构建出一个SVM分类器。通过调整参数(如 C 和核函数的参数),进行模型的训练和优化。
,构建出一个SVM分类器。通过调整参数(如 C 和核函数的参数),进行模型的训练和优化。
使用测试集评估模型的性能,可以考虑准确度、精确度、召回率等指标,得到模型在不同风险水平下的分类效果。
解释模型的结果,可以通过查看支持向量、超平面的方向等来理解不同因素对风险的贡献程度。
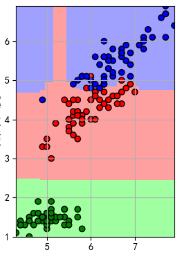
1. 决策边界可视化:
绘制特征空间中的决策边界,以显示模型是如何将不同类别的样本分开的。对于二维特征空间,可以使用散点图和等高线图来显示决策边界。
2. 学习曲线:
绘制模型的学习曲线,显示随着训练样本数量的增加,模型的性能如何变化。这有助于判断是否需要更多的数据来改善模型。
3. **混淆矩阵:**
绘制混淆矩阵可以更详细地查看模型在每个类别上的性能,包括真正例、假正例、真负例和假负例。
建立SVM回归模型来评估特定区域建筑物的风险水平,需要一些具体的建模步骤和数学公式。以下是建模思路,结合公式和分析:
1. 数据收集和准备:
- 特征选择: 选择与建筑物风险相关的特征,可能包括气象数据、地理信息、建筑结构信息等。设特征为  ,其中 m 是特征的数量。
,其中 m 是特征的数量。
- 目标变量: 选择建筑物风险水平作为目标变量,设目标变量为  。
。
2. 特征标准化:
- 使用标准化处理确保不同特征的尺度一致,以避免某些特征对模型的影响过大。

其中,  是特征的均值, 是特征的标准差。
是特征的均值, 是特征的标准差。
3. SVM回归模型:
- SVM回归的目标是找到一个函数 f(X),使其预测的值  尽可能接近实际观测值
尽可能接近实际观测值  。
。
- 用  表示第 i 个样本, 表示该样本的真实建筑物风险水平。
表示第 i 个样本, 表示该样本的真实建筑物风险水平。

其中,w 是权重向量,b 是偏置。
4. 损失函数:
- 损失函数衡量模型预测值和真实值之间的差异。对于SVM回归,常使用 epsilon-insensitive loss 函数:

其中, 是一个控制模型对误差的容忍度的参数。
是一个控制模型对误差的容忍度的参数。
5. 目标函数:
- SVM回归的目标是最小化损失函数和正则化项,以确保模型具有较好的泛化能力。

其中,C 是正则化参数,用于平衡模型的拟合程度和泛化能力。
6. 模型训练:
- 使用训练数据对模型进行训练,优化目标函数。
- 可以使用优化算法,如梯度下降法等。
7. 模型评估:
- 使用测试集评估模型的性能,可以使用均方误差(Mean Squared Error, MSE)等指标。

8. 结果解释:
- 解释模型的权重向量 w,了解哪些特征对建筑物风险的贡献最大。
 可视化SVM回归模型
可视化SVM回归模型
使用SVM解决问题三,即确定建筑物是否应该受到保护,可以将其构建为一个二分类问题。以下是详细的思路,包括公式和步骤:
1. 数据准备:
- 特征选择: 选择能够反映建筑物文化、历史、经济或社区重要性的特征。这可能包括建筑的年代、历史性质、社区反馈等。
- 标签定义: 为每个建筑物定义标签,例如,1表示“应该保护”、0表示“不需要保护”。
2. 特征标准化:
- 使用标准化处理确保不同特征的尺度一致,以避免某些特征对模型的影响过大。
3. SVM分类模型:
- SVM的目标是找到一个分隔超平面,使得两类样本的间隔最大化。

其中,w 是权重向量,b 是偏置,C 是正则化参数, 是第 i 个建筑物的特征,
是第 i 个建筑物的特征, 是其标签。
是其标签。
4. 超参数调优:
- 可以使用交叉验证和网格搜索等技术对SVM的超参数进行调优,例如调整正则化参数 C。
5. 模型训练:
- 使用训练数据对SVM分类器进行训练,优化目标函数。
6. 模型评估:
- 使用测试集评估模型的性能,考察其准确性、召回率、精确度等指标。
7. 模型解释:
- 解释SVM模型的结果,了解哪些特征对于建筑物是否应该被保护具有重要性。可以通过查看权重向量 w 的分量来获取特征的贡献度。
8. 部署和应用:
- 将训练好的SVM模型部署到实际应用中,以辅助社区领导者做出决策。
9. 结果可视化:
- 可以通过绘制决策边界、支持向量等方式可视化模型的分类效果。
可视化:对于问题三,我们使用了SVM进行分类,涉及到二维特征的情况,我们可以使用散点图和决策边界的可视化来展示模型的效果。以下是一个完整的可视化代码示例:
这个代码中,`plot_decision_boundary` 函数用于绘制决策边界和支持向量。通过不同的颜色和标记,我们可以清晰地看到模型是如何将不同类别的样本分隔开的,并且哪些样本是支持向量。
学习曲线可视化是评估模型性能和判断模型是否过拟合或欠拟合的一种重要方式。在支持向量机 (SVM) 模型中,学习曲线通常绘制训练集和验证集的准确度随着训练样本数量的变化而变化的曲线:
这个代码中,`learning_curve` 函数从训练集中随机选择样本,计算模型在不同训练集大小下的训练和验证准确度。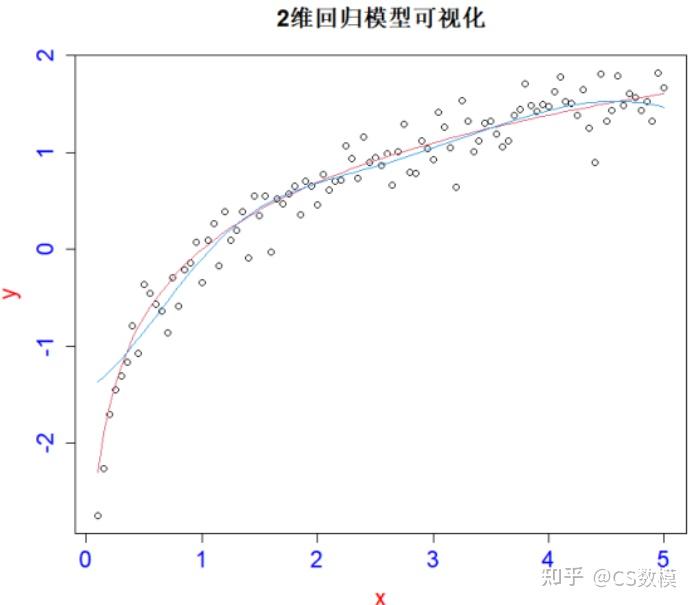 SVM回归模型可视化
SVM回归模型可视化
针对问题四,即如何确定建筑物是否应该受到保护,我们可以采用神经网络模型进行建模。以下是基于问题题目的建模思路:
1. 数据准备: 收集与建筑物相关的数据,包括文化、历史、经济等方面的特征,以及每个建筑物是否受到保护的标签。确保数据集的质量,包括清理缺失值、处理异常值等。
2. 数据标准化: 对特征进行标准化,确保它们具有相似的尺度,以提高神经网络的训练效果。
3. 构建神经网络模型: 使用深度学习框架构建适用于二分类问题的神经网络模型。考虑以下架构:
- 输入层:特征数量对应的神经元。
- 隐藏层:选择适当数量的隐藏层和神经元,使用合适的激活函数,如ReLU。
- 输出层:一个神经元,使用Sigmoid激活函数进行二分类。
4. 模型训练: 使用训练集对模型进行训练。监控训练过程,确保模型在训练集和验证集上都有良好的性能。
5. 模型评估: 使用测试集评估模型的性能。查看准确度、精确度、召回率等指标。
6. 建议和解释: 利用训练好的模型对新的建筑物数据进行预测。通过阈值设定,将模型输出的概率解释为建筑物应该受到保护的置信度。根据模型的输出,给出建议,例如建议对置信度高的建筑物进行保护。
7. 模型解释: 在建议中,考虑将模型的决策过程以可解释的方式呈现,以增加决策的透明度和可理解性。可以使用SHAP(SHapley Additive exPlanations)等方法进行模型解释。
这个建模思路基于深度学习的神经网络,可以更好地捕捉特征之间的复杂关系,从而提高建筑物是否应受到保护的准确性。然而,模型的性能还需要通过实际数据的训练和测试来验证和优化。
可视化:
1. **学习曲线:** 学习曲线可视化模型在训练和验证集上的损失(loss)变化。这有助于判断模型是否过拟合或欠拟合。
2. **准确度曲线:** 如果是分类问题,可以绘制模型在训练和验证集上的准确度。
3. **混淆矩阵:** 对于分类问题,绘制混淆矩阵可以帮助了解模型在不同类别上的性能。
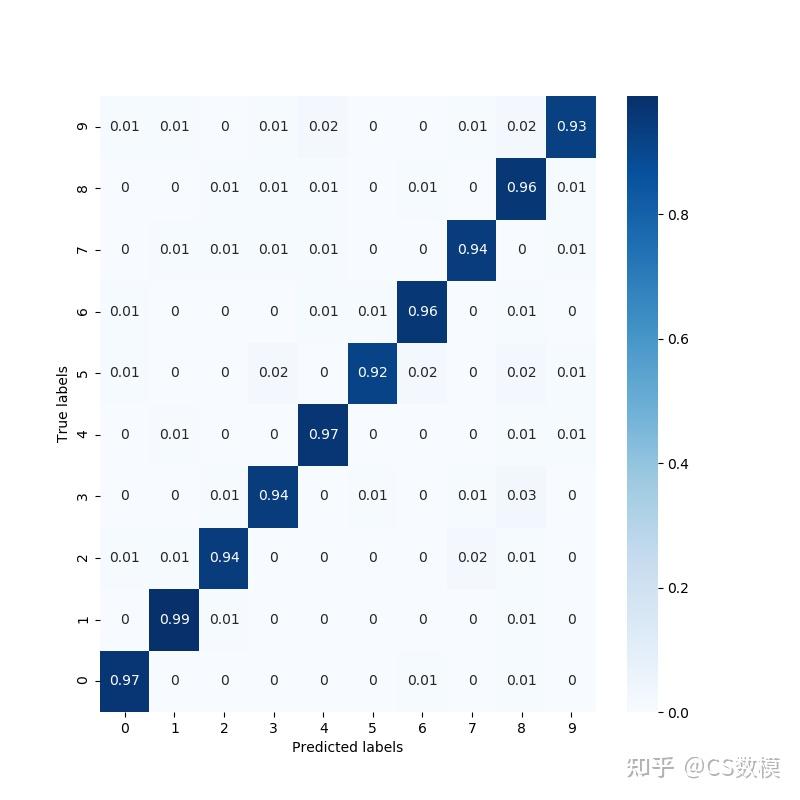
4. **ROC曲线和AUC:** 对于二分类问题,绘制ROC曲线和计算AUC值可以帮助评估模型的性能。
问题五涉及对历史建筑的保护措施和未来发展的建议。为了解决这个问题,我们可以使用神经网络模型,但与问题四不同,这次我们需要进行多标签分类。每个历史建筑可能涉及多个方面的保护和考虑。以下是建模思路:
1. 数据准备: 收集包含历史建筑的各种特征以及与其相关的多个标签的数据。标签可能包括文化保护、历史保护、经济考虑等。确保数据集的质量,包括清理缺失值、处理异常值等。
2. 数据标准化: 对特征进行标准化,确保它们具有相似的尺度。
3. 多标签分类模型: 构建神经网络模型,适用于多标签分类问题。考虑以下架构:
- 输入层:特征数量对应的神经元。
- 隐藏层:选择适当数量的隐藏层和神经元,使用合适的激活函数,如ReLU。
- 输出层:多个神经元,每个代表一个标签,使用Sigmoid激活函数进行多标签分类。
4. 模型训练: 使用训练集对模型进行训练。由于这是一个多标签分类问题,需要使用适当的损失函数和评价指标。
5. 模型评估: 使用测试集评估模型的性能。考虑每个标签的准确度、精确度、召回率等指标。
6. 模型预测和建议: 使用训练好的模型对新的历史建筑数据进行预测,得出每个标签的概率。根据概率和领域知识,提出对历史建筑的保护和发展建议。
7. 模型解释: 对于每个历史建筑,通过模型输出的概率解释模型的决策过程,以增加决策的透明度和可理解性。
基于神经网络的多标签分类,可以更好地捕捉历史建筑在多个方面的复杂关系,从而提高模型的预测性能。。
在多标签分类问题中,可视化主要侧重于模型性能和预测结果的分析:
1. 学习曲线: 可以绘制训练损失和验证损失的学习曲线,以监视模型的训练过程。
2. 准确度曲线: 如果是分类问题,可以绘制模型在训练和验证集上的准确度。
3. 混淆矩阵: 对于多标签分类问题,可以绘制每个标签的混淆矩阵,以了解模型在每个标签上的性能。
4. ROC曲线和AUC: 对于每个标签,可以绘制ROC曲线和计算AUC值。
在处理多标签分类问题时可以具有比较良好的表现,并且充分的进行了对比。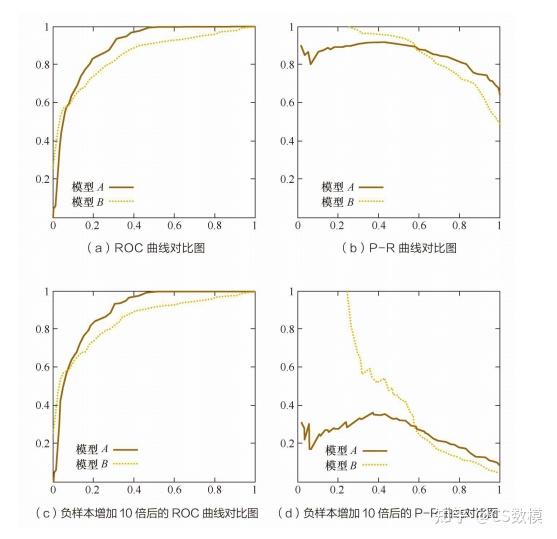
A-F题思路、代码、选题建议、部分成品论文均已更新,其他陆续更新中
下文包含:2024美国大学生数学建模竞赛(以下简称美赛)思路解析、美赛参赛时间及规则信息及如何准备美国大学生数学建模竞赛
C君将会第一时间发布选题建议、所有题目的思路解析、相关代码、参考文献、参考论文等多项资料,帮助大家取得好成绩。2024年美国大学生数学建模竞赛于2号早上6点正式开赛
详细内容请看我的这篇文章:2024美国大学生数学建模竞赛思路助攻汇总
很高兴,以前的回答帮助了上万支队伍,下面展示了之前的回答:2022年美赛C题思路
分工可以参考以前发布的美赛分工文章:(比赛时长相同)2023美赛时间分工安排
请看这篇文章:2024美国大学生数学建模竞赛思路助攻汇总2024美国大学生数学建模美赛选题建议+初步分析
B题思路:https://zhuanlan.zhihu.com/p/681095049
B题代码:https://zhuanlan.zhihu.com/p/681199890
C题思路:https://zhuanlan.zhihu.com/p/681026037
C题代码:https://zhuanlan.zhihu.com/p/681107546
E题思路:https://zhuanlan.zhihu.com/p/681078439
E题代码:https://zhuanlan.zhihu.com/p/681200129
2月2早6点-2月6早10点
竞赛结果:日期待定。
美国大学生数学建模竞赛目前分为两种类型,MCM(Mathematical Contest In Modeling)和 ICM(Interdisciplinary Contest In Modeling),两种类型竞赛采用统一标准进行,竞赛题目出来之后,参数队伍通过美赛官网进行选题,一共分为 6 种题型。
MCM:A:连续型B:离散型C:大数据
ICM:D:运筹学/网络科学E:环境科学 F:政策
针对chatgpt等大语言模型
随着AI工具的飞速发展,美赛也逐渐认可了它的应用潜力和工具合理性。此次AI工具的准入与规范新规,不仅将为参赛者处理分析数据、优化建模等提供重大帮助,同时也对解决方案的创新性、写作的逻辑思辨等方面提出了新的挑战。
新规之下,参与美赛的过程更加便捷高效,但除了此种优势之外,又引发了针对AI工具老生常谈的争议:伦理问题和原创性问题。关于这个问题,美赛官方也是十分审慎的,给出了清楚明晰的具体使用要求规范文件。
组委会要求:报告中必须明确说明AI工具使用情况,具体到模型和用途,并标注引用及参考文献,除了常规的引用要求外,还要在方案末尾附上“人工智能使用报告”(不包含在25页解决报告内)。
另外官方文件还指出了一些使用AI工具的范围和可能存在的风险,例如AI工具源库数据准确性有误或工具大量复制未知来源文本导致的抄袭等等。
C君观点:
优势:数据处理和分析:帮助参赛队伍对数据进行预处理、特征提取和降维等操作,提高大规模数据处理效率。模型优化和参数调整:协助参赛队伍寻找最佳的模型结构和参数配置。翻译等大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
劣势:问题复杂度问题、创造性与灵活性问题、查重问题
论文检索工具:推荐谷歌学术(需科学上网) 国内的镜像网站
数据搜集整理:团队会搜集全网最全比赛时相关的数据集与数据来源,以供大家使用。其他的比如kaggle、百度飞桨等数据竞赛中也有大量数据集
辅助写作工具:chatgpt等(谨慎使用)
翻译工具:deepl + chatgpt
流程图制作:visio
l 看哪些?
国赛:看每年的高教社杯和matlab创新奖,如果有时间看看相应题目官网给出的优秀论文
美赛:看o奖论文(最好是冠名奖)
研赛:看一等奖论文
l 怎么学?
1 学习整体框架。根据3-5篇论文整理出一套可以在比赛时直接用的写作模版
2 学习写作格式。方法同上
3 学习语言表达。整理优秀的论文中的措辞,以及用什么什么方法,有什么好的表述方法没有。建议最后将一些好的表达放在一个整理的文档中,方便变比赛时使用
4 学习算法及模型。这里尤其要强调,并不是需要学习优秀论文涉及的所有算法,一般只需要学习用了现在常用的算法(比如元胞自动机等)流程、实现及表述即可,将其按照算法进行分类整理。(之后C君可能会开数模算法模版+算法写作通用模版系列)很多论文有部分仅适用于那个问题,自创的模型,这种费时费力,收效甚微,不建议学习
5 学习摘要的表述
6 学习可视化用的工具及如何去展示
l 怎么看?
(建议队伍一起学习,一个题目用时4-6天)
step1 根据题目,写出自己对问题的分析,然后查阅资料,改进自己的问题分析【半天】
step2 和队友讨论,形成自己队伍对于问题的解决方案(不需要具体做,写出问题分析即可)【半天】
step3 阅读优秀论文(第一部分提到了怎样才算优秀论文),注意此时不要看优秀论文的摘要,从问题分析开始看起。然后根据第二部分提到的方向分别进行整理【两天】
step4 优秀论文的思路与自己的思路进行对比【半天】
step5 根据优秀论文后面的内容,给此优秀论文写摘要。写完后对比论文的摘要,总结自己表述的优缺点【半天】
step6可选任务 再挑两篇优秀论文进行学习,从step3到step5,此时取长补短,浓缩精华即可【2天】
其他详细内容可以看我以前的文章:如何从零开始准备大学生数学建模比赛?
https://zhuanlan.zhihu.com/p/468906708
如需第一时间获得资料和其他相关内容,可以点击下方卡片了解详情:https://zhuanlan.zhihu.com/p/607034449
下面送给大家一些,C君看到的好玩的建模表情包,欢迎大家补充。私聊发图或者评论发图(好像需要一定的盐值)都是可以的,我会选择一些补充上去。

A-F题思路、选题建议、部分题目代码已更新,其他陆续更新中
下文包含:2024美国大学生数学建模竞赛(以下简称美赛)思路解析、美赛参赛时间及规则信息及如何准备美国大学生数学建模竞赛
C君将会第一时间发布选题建议、所有题目的思路解析、相关代码、参考文献、参考论文等多项资料,帮助大家取得好成绩。
需要团队最新的更新数据集、思路、代码、论文等,可以看我的这篇文章:(第一时间更新)2024美国大学生数学建模竞赛思路助攻汇总
D题参考论文:
选题建议如下:2024美国大学生数学建模美赛选题建议+初步分析
ABCDEF题思路如下:2024美国大学生数学建模竞赛思路助攻汇总
C题思路:2024美赛C题保姆级分析完整思路代码数据教学
很高兴,过去四年的回答帮助了上十万支队伍,下面展示了之前美赛的回答:2022年美赛C题思路
下面将给到大家一些团队的国一选手之前的参赛经历及如何准备数学建模竞赛的方法:
本文非常适合各个阶段的建模er观看,干货满满!(超详细攻略,完整版在下方回答):如何评价2022年数学建模国赛?
如下为2023美赛的分工建议:(类比一下,得到今年美赛的 比赛时长、英文论文这些都是和美赛类似的)
比赛时间:2023年2月17日 6:00 ~ 2月21日 9:00
一、赛前一天,16日
17日晚上,保证充足睡眠。
二、比赛第一天,17日
选题阶段:
6:00下载和翻译题目,半小时内每个人翻译2个题目,建议自行翻译后结合网上翻译,因为网上最早的都是机翻,关键数据和点位有可能与题意有出入。
剩余请看这个文章:2023美赛时间分工安排
总结必用的算法和模型,可以收藏此篇,教你如何进行操作!通过总结分成两大处理、四大模型、六大算法,如下: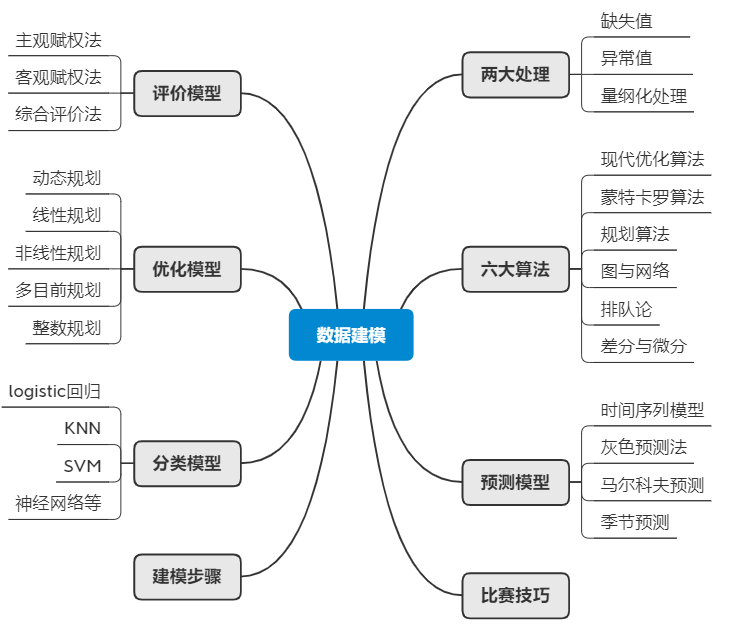
一般可以利用优化模型得到最优目标,比如在经济问题、生产问题、投入产出等等,人们总希望用最小的投入得到最大的产出,一般分析的流程如下: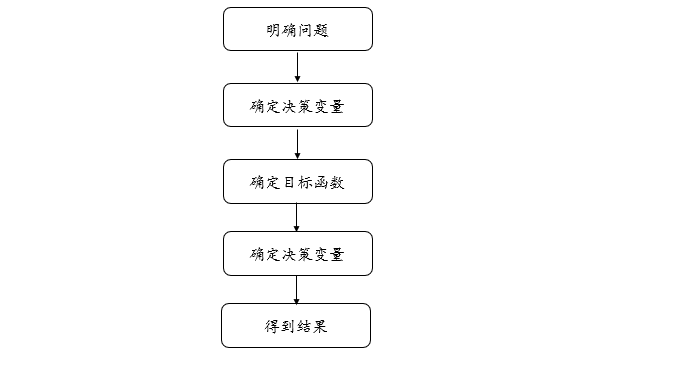
其中决策变量一般有0-1规划或者整数规划,通过目标函数和约束条件,确定优化模型的类型,一般有动态规划,线性规划,非线性规划以及多目标规划。动态规划
以时间划分阶段的动态优化模型。可以解决最小路径问题、生产规划问题、资源配置问题。虽然动态规划用于求解以时间划分阶段的动态过程的优化问题,但是如果对于线性规划、非线性规划引入时间因素,也可以把他视为多阶段决策过程。最小路径模型图类似如下: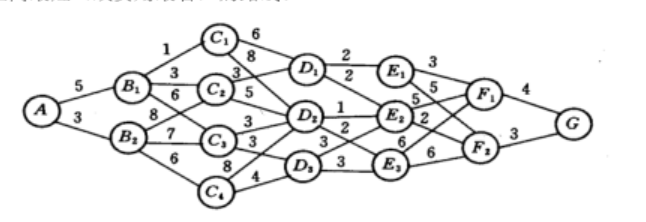 线性规划
线性规划
目标函数和约束条件均为线性。线性规划的目标函数可以是求最大值,也可以是求最小值,约束条件的不等号可以是小于号也可以是大于号。其标准形式如下: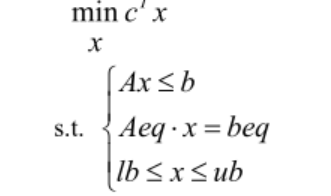
其中c和x为n维列向量,A、Aeq为适当维数的矩阵,b、beq为适当维数的列向量。非线性规划
目标函数和约束条件均不是线性,非线性规划比线性规划偏难,线性规划与非线性规划的区别为:如果线性规划的最优解存在,其最优解只能在其可行域的边界上达到(特别是可行域的顶点上达到);而非线性规划的最优解(如果最优解存在)则可能在其可行域的任意一点达到。多目标规划
目标函数不唯一,此种算法主要是解决线性规划的局限性,线性规划只能解决最大值、最小值问题,有些问题需要衡量多目标规划,一般需要将此种需要转化为单目标模型,所以需要有加权系数,表述不同目标之间的重要程度对比。整数规划
决策变量取值为整数。整数规划最优解一般不能按照实数最优解简单取整而获得,所以一般求解方法有分枝定界法、割平面法、隐枚举法(一般解决0-1整数规划问题)、蒙特卡罗法(可以求解各类型规划)。
一般常用的算法有现代优化算法、蒙特卡罗算法、规划算法、图与网络、排队论以及差分和微分等。
现代优化算法一般包括遗传算法、模拟退火法、禁忌搜索法、蚁群算法等。一般遗传算法通常解决决策变量为离散变量时,跳出局部最优解的能力较强,模拟退火法跳出局部最优解能力最强,紧急搜索法是组合优化算法的一种,可以记录已经打到过的局部最优点。
蒙特卡罗算法主要手段是随机抽样和统计实验,利用计算机实现统计模拟或抽样,得到问题的近似解,可以进行微分方程求解,可以将微分方程转化为概率模型,然后通过模拟随机过程得到方程近似解同事也可以解决积分方程非线性方程组等等。
规划算法一般用于解决优化模型,常用的动态规划、线性规划、非线性规划、多目标规划、整数规划等。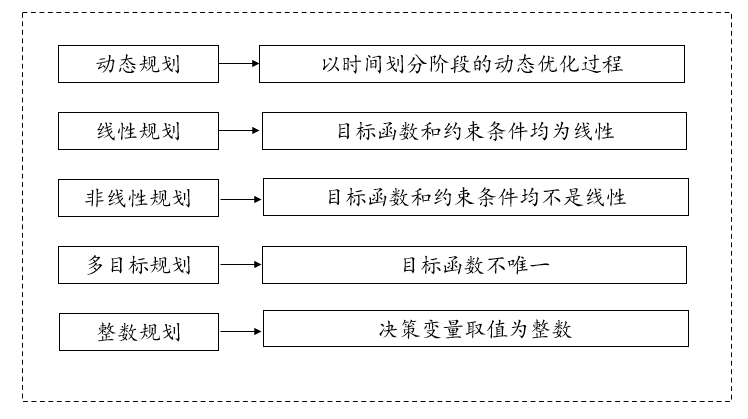
图与网络算法可以解决最小路径问题,最优着色问题,最大流问题,以及最小生成树等问题,但是其计算复杂度较高,并且消耗大量资源和储存空间。
排队论研究的内容包括性态问题、最优化问题以及排队系统的统计推断,排队论主要是解决服务系统的排队问题,通过分析排队系统的概率规律性和优化问题,提出最优的排队策略,同时也可以提供精确的数学模型,对排队系统的性能进行定量分析和预测,如平均等待时间、平均队列长度、平均服务时间等。但是使用该算法需要很多参数,需要保证参数的精确性。
差分算法可以解决连续型问题,能够用迭代的方式求解方程,避免了微分方程中的导数,更便于计算。例如商品销售量的预测等,微分算法适用于基于相关原理的因果预测模型,大多是物理或几何方面的典型问题,可以通过数学符号表示规律,列出方程,求解的结果就是问题的答案,可以处理连续型问题,假设条件清晰,规律性强。但是涉及求导所以计算更复杂。
无论是赛题给你数据还是自己搜集数据,一般都需要数据的清洗和数据的变换,尤其是C题,具体说明如下:
数据清洗一般包括缺失值处理和异常值处理,如果数据中有缺失值,可以进行删除处理,或者平均值、中位数、众数等填充,其中众数一般适用于分类数据,除此之外,还可以使用线性插值、牛顿插值、拉格朗日插值法进行插值可以参考下方资料。
数据变换:有些数据在分析前还需要进行变换,处理量纲问题等,比如因子分析或者主成分分析前需要将数据标准化,一些综合评价法也需要将数据进行处理,比如指标为正向(越大越好),则可以进行正向化处理,有些指标为负向(越小越好),则可以进行逆向化处理等等,可以参考下方资料。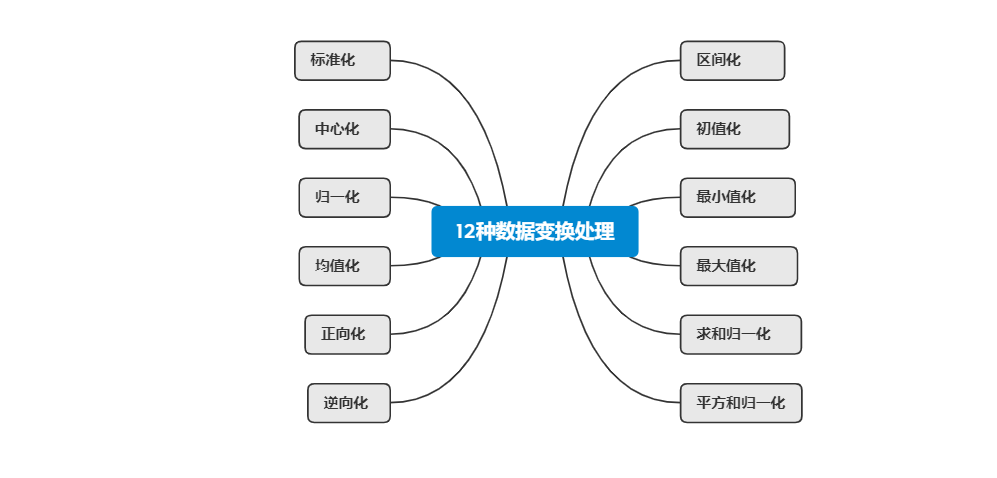
标准化:此种处理方式会让数据呈现出一种特征,即数据的平均值一定为0,标准差一定是1。针对数据进行了压缩大小处理,同时还让数据具有特殊特征(平均值为0标准差为1)。在很多研究算法中均有使用此种处理,比如聚类分析前一般需要进行标准化处理,也或者因子分析时默认会对数据标准化处理。
归一化:当某数据刚好为最小值时,则归一化后为0;如果数据刚好为最大值时,则归一化后为1。归一化也是一种常见的量纲处理方式,可以让所有的数据均压缩在【0,1】范围内,让数据之间的数理单位保持一致。
中心化:此种处理方式会让数据呈现出一种特征,即数据的平均值一定为0。针对数据进行了压缩大小处理,同时还让数据具有特殊特征(平均值为0)。
正向化:适用于当指标中有正向指标,又有负向指标时;此时使用正向化让正向指标全部量纲化;也或者指标全部都是正向指标,让所有正向指标都量纲化处理。
逆向化:一般多应用于评价模型中,逆向的指标逆向化,这种方法适用于指标值越小越好的情况,比如工厂的污染情况等。
适度化:这种方法适用于指标值差异较大的情况,比如消费者对某产品的满意度等。
区间化:目的是让数据压缩在【a,b】范围内,a和b是自己希望的区间值,如果a=0,b=1,那么其实就是一种特殊情况即归一化;其计算公式为a + (b - a) * (X - Min)/(Max - Min)。
参考资料
SPSSAU:异常值的识别与处理,看这一篇就够了
SPSSAU:12种数据量纲化处理方式
SPSSAU:量纲化处理汇总
评价类模型一般包括权重计算和进行综合评价对比,分析前搜集原始数据,然后对数据进行预处理,比如标准化,正向化逆向化等等,一般评价类模型,需要将计算权重的模型和进行综合评价的模型相结合分析,比如熵权topsis法等,计算权重包括主观方法和客观方法,各自有各自的优缺点,但在分析中往往二者相结合进行分析对比更为准确,一般最终目的得到综合评价结果。具体如下: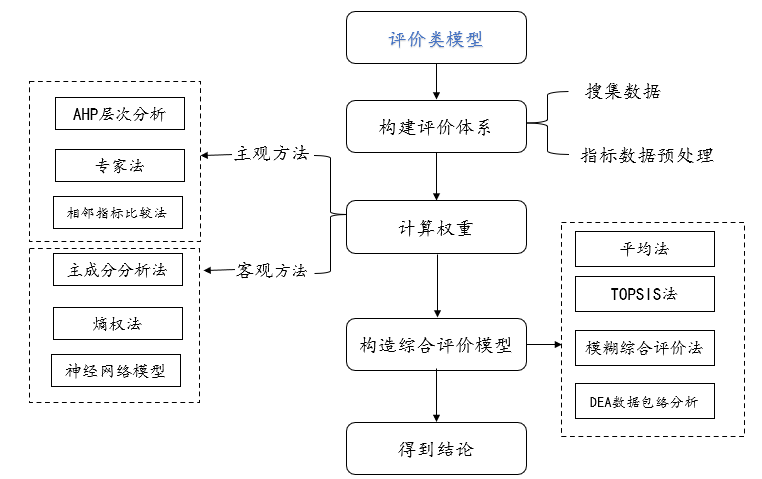
评价模型的方法说明如下: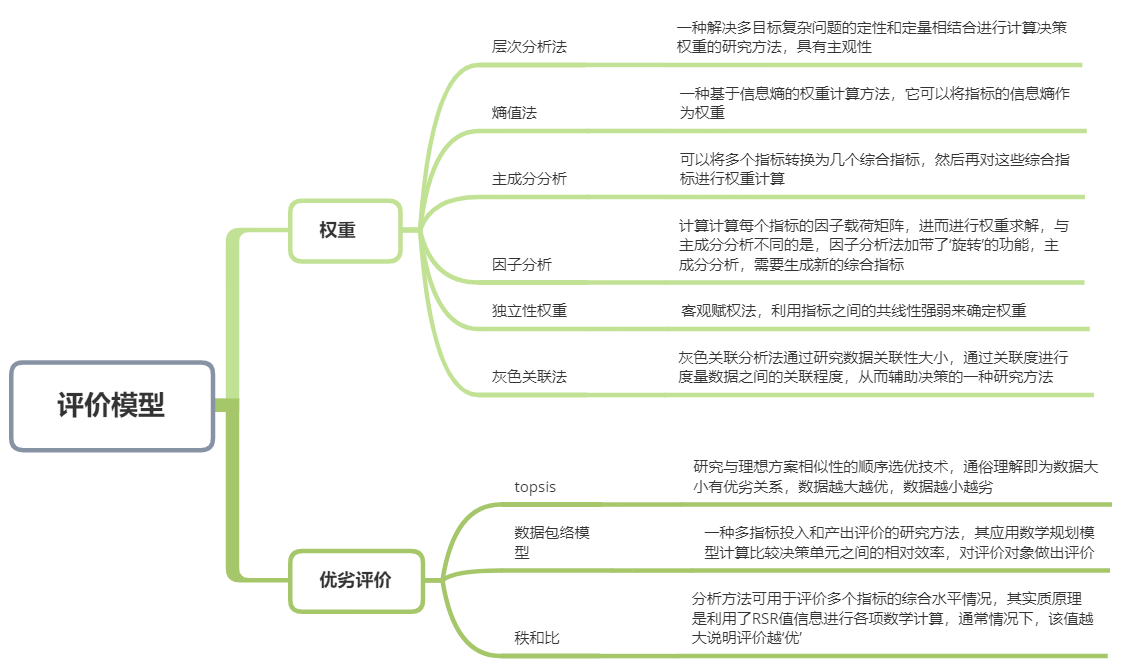
一般在分析评价类模型是通常采用组合赋权法,即通过主观赋权法和客观赋权法综合得到权重,然后结合综合评价方法得到结论。参考资料如下:
SPSSAU:AHP中特征向量、权重值、CI值等指标如何计算?
SPSSAU:模糊综合评价指标如何计算?四种模糊算子如何计算?
SPSSAU:数学建模|权重计算与评价模型方法总结
SPSSAU:手把手教你用熵值法计算权重
SPSSAU:手把手教你用熵值法和主成分分析计算权重
SPSSAU:如何搞定熵权topsis?
5、预测模型
预测模型一般包括回归预测模型、时间序列预测模型,灰色预测法、马尔科夫预测、机器学习(神经网络、决策树)等。一般预测模型的流程如下: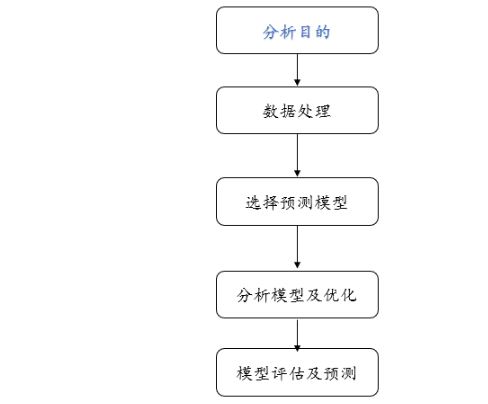
时间序列模型
时间序列模型是一种根据系统观测得到的时间序列数据,通过曲线拟合和参数估计来建立数学模型的理论和方法。它一般采用曲线拟合和参数估计方法,如非线性最小二乘法,来对时间序列数据进行拟合,从而建立相应的数学模型。适合中长期预测。
参考资料:
SPSSAU:必看!时间序列分析!
灰色预测法
灰色预测模型为小样本预测模型,适合短期预测,其利用微分方程来充分挖掘数据的本质,建模所需信息少,精度较高,运算简便,易于检验,也不用考虑分布规律或变化趋势等。
参考资料:
SPSSAU:超级干货:一文读懂灰色预测模型
马尔科夫预测
马尔科夫预测是一种基于马尔科夫链的预测方法,主要用于预测随机过程未来的状态。这种方法假设一个系统的下一个状态只与前一个状态有关,而与之前的状态无关。
参考资料:
SPSSAU:马尔可夫预测应该如何做?
其它:
SPSSAU:指数平滑指标怎么看?
SPSSAU:手把手教你支持向量机模型 SVM
建议选择预测模型时也建立分析流程,比如进行时间序列预测: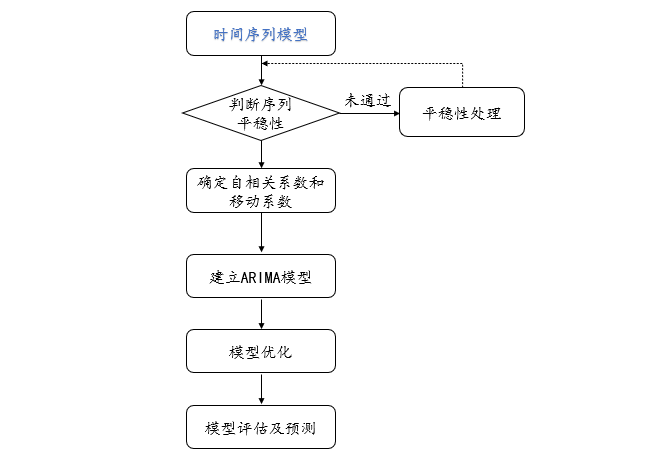
分类模型一般可以解决国赛数学建模的小问,一般常用的方法有聚类分析、判别分析以及机器学习(决策树、神经网络等)等。聚类分析前提不明确数据对象应该分为几类,常用的计算有欧式距离、pearson相关系数、夹角余弦法等,判别分析一般是分析前就明确观察对象应该分为几类,一般在分析中可以将二者结合进行分析以及还有机器学习可以进行分类。
建模的六个步骤一般如下: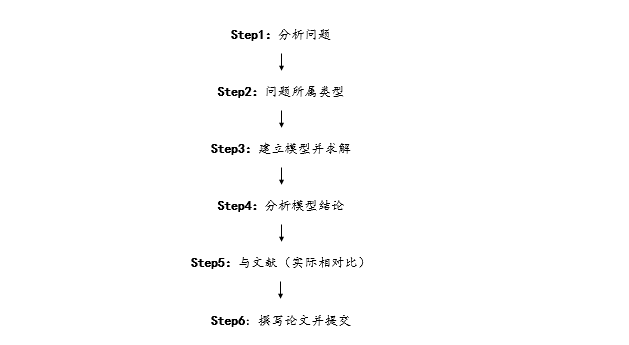
1、多画图
可以在论文中多画图进行描述问题,更加直观,可以使用SPSSAU、python、以及R和MATLAB等等。
2、排版
可以使用LaTeX或者Markdown文档,LaTeX数学符号和命令很方便,还可以处理复杂的数学公式和图表。Markdown与LaTeX相比,Markdown语法简单,易于上手。它可以将Markdown文本轻松转换为HTML、PDF等格式的文档。还有其他的软件,比如Office、WPS等,但它们可以根据个人习惯和需求,选择适合自己的排版软件即可。
3、摘要
一定要重视摘要,因为评委可能看你的论文的速度特别特别快,如果没有亮点很大可能不能拿奖,一定要写明自己分析什么问题,如何解决,用了哪些方法,得到了什么结论,并且整篇论文的格式也需要规规整整,可以多读几篇优秀论文然后在进行书写。
祝大家取得好成绩!!SPSSAU

他们所有微分方程的参数都是人为设定的,如何能够评价七鳃鳗对生态系统的真实影响,以及分析出七鳃鳗的物种优势和劣势呢???
而我们这里通过将近半天的搜索数据,查到了美国五大湖中优势物种的食物网数据,以Eric伊利湖为例,共包含34各优势物种,相互之间的关系如下图所示: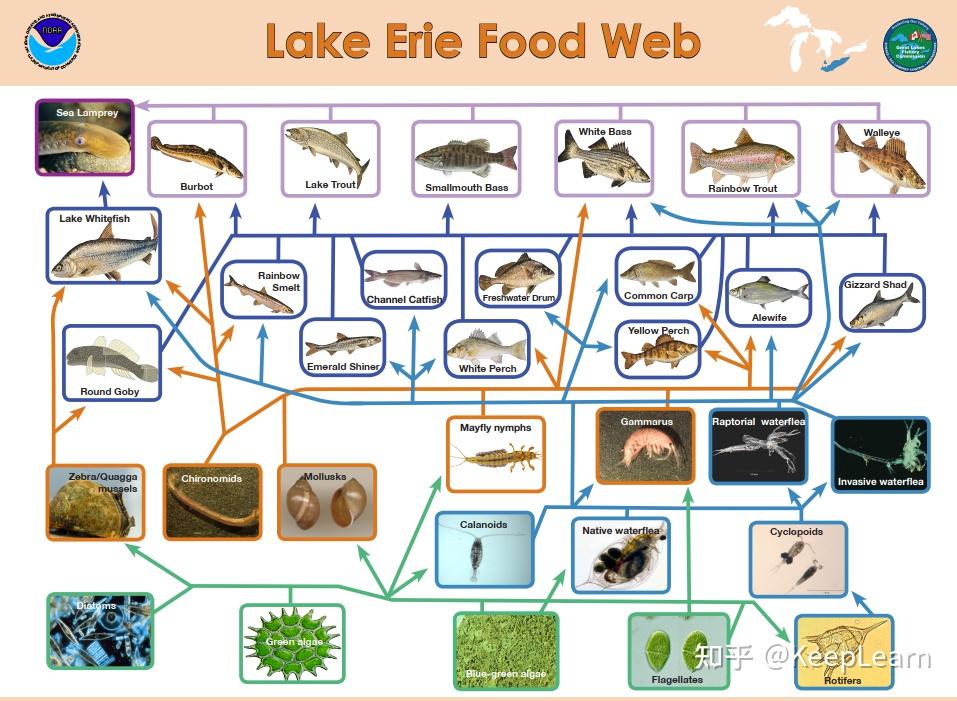
选题是很重要的一个环节,适当的选题不仅可以避免之后临阵换题的慌乱,还可以提高获奖概率。
可否通过选题提高获奖概率呢?
答案肯定是可以的,根据往年国赛的数据进行分析可以得出以下结论:
选哪个题的队伍少,就选哪个题。观察数据发现,选择某题的队伍数量恰与选择该题队伍的获奖比例成反比,具体数据可以阅读以下文章。
国赛推理得到的结论对于美赛也有部分适用。
具体到本次比赛,下面进行题目分析。
这个数学建模赛题探讨了海洋七鳃鳗性别比例对局部环境的依赖性以及该变异对生态系统的影响。主要关注于性别比例对资源可利用性的响应,并针对性别比例变化引起的生态系统内相互作用开展研究。需要建立的数学模型包括考虑到资源可利用性变化的性别比例模型以及生态系统稳定性模型。解题时可能使用的算法包括概率模型、生态系统动力学模型、以及数值模拟算法等。
针对第一个问题,我们可以建立一个性别比例模型,考虑到资源可利用性对雌性和雄性七鳃鳗生长速率的影响,然后将该模型与生态系统动力学模型结合,分析性别比例变化对生态系统的影响。
对于第二个问题,我们可以进一步分析在性别比例变化下,雌性和雄性七鳃鳗的生存优势和劣势,可能需要建立一个生存率模型,并结合资源利用模型,探讨各个性别在不同资源条件下的生存策略。
针对第三个问题,我们需要建立一个生态系统稳定性模型,考虑性别比例变化对食物链和生物多样性的影响,并利用数值模拟算法探索不同性别比例对生态系统稳定性的影响。
对于第四个问题,我们可以分析性别比例变化对生态系统中其他生物群体的影响,可能需要建立一个生态相互作用模型,并结合概率模型探讨性别比例变化对寄生生物等其他生物的影响。
赛题全文+赛题分析+解题思路,可以看我的这篇文章:
KeepLearn:【解题思路】2024年数学建模美赛MCM/ICM A题 七鳃鳗性别比与资源可用性(后续更新程序和参考论文)
这个数学建模赛题涉及希腊公司 Maritime Cruises Mini-Submarines (MCMS) 的迷你潜水艇在探索爱奥尼亚海底沉船时的安全性建模。首先需要建立一个预测潜水艇位置随时间变化的模型,考虑到海底地形、水流、密度等因素。其次,需要分析预测中存在的不确定性,并探讨潜水艇在通信中断情况下如何减少不确定性的方法,以及所需的设备。接着,需要提出额外的搜索设备建议,包括设备类型、成本以及如何准备和使用。最后,需要开发一个根据位置模型推荐搜索设备部署和搜索模式的模型,以最小化寻找丢失潜水艇所需的时间,并确定随时间和累积搜索结果变化的潜水艇发现概率。
对于第一个问题,我们需要建立一个包含水流、密度、地形等影响因素的潜水艇位置预测模型,可能需要使用数值模拟算法和流体动力学模型来模拟海洋环境。不确定性通常来自于海洋环境的变化和模型的精度。潜水艇可以定期向主机船发送信息,如水深、温度、压力等,以减少预测不确定性,所需设备可能包括传感器和通信设备。
对于第二个问题,我们需要考虑额外搜索设备的成本、可用性和维护成本。建议可以包括潜水员、声纳设备、无人机等。救援船可能需要携带救援设备如潜水员、潜水艇、救生艇等。
对于第三个问题,我们可以结合位置模型和搜索设备性能,建立一个最优搜索路径的模型,可能需要使用优化算法如遗传算法或模拟退火算法。概率模型可以用来估计随时间变化的潜水艇发现概率。
对于第四个问题,我们可以调整模型以适应其他目的地如加勒比海,并考虑多个潜水艇同时活动时的影响。可能需要增加模型复杂度以考虑多潜水艇的交互作用和资源竞争。
赛题全文+赛题分析+解题思路,可以看我的这篇文章:
KeepLearn:【解题思路】2024年数学建模美赛MCM/ICM B题 搜寻载人潜水器(后续更新程序和参考论文)
这个数学建模赛题围绕2023年温网男子单打决赛展开,其中20岁的西班牙新星卡洛斯·阿尔卡拉斯击败了36岁的诺瓦克·德约科维奇,结束了德约科维奇自2013年以来在温网的连胜纪录。比赛过程中出现了许多令人惊讶的变化,这种变化通常被归因于“势头”现象。赛题要求利用提供的数据集,开发一个模型来捕捉比赛中的战局流向,评估势头在比赛中的作用,并预测比赛中势头的变化。
解决这个问题需要建立数学模型来分析比赛中的得分情况和势头变化,可能涉及到时间序列分析、统计模型、以及机器学习方法等。对于每个小问题,需要利用提供的数据集来进行建模和分析,并提供可视化展示和统计指标来支持结论。
对于第一个问题,需要开发一个模型来捕捉比赛中的战局流向,评估每个时刻哪位球员表现更好以及有多好。可能的方法包括建立一个时间序列模型来跟踪比赛中的得分情况,并考虑到发球方的优势。可视化可以通过绘制得分情况的图表来展示比赛流向。
第二个问题涉及评估“势头”在比赛中的作用,可以利用模型来比较实际得分情况与模拟随机得分情况的差异,进而评估势头是否具有统计意义。
第三个问题需要开发一个模型来预测比赛中势头的变化,可能需要考虑到比赛中的各种因素如球员状态、场地情况等。可以使用机器学习方法来挖掘与势头变化相关的因素,并建立预测模型。大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
第四个问题涉及将模型应用到其他比赛,并评估模型的泛化能力。可能需要考虑到不同比赛、不同球员以及不同球场的情况,并对模型进行调整和改进。
赛题全文+赛题分析+解题思路,可以看我的这篇文章:
KeepLearn:【解题思路】2024年数学建模美赛MCM/ICM C题 网球运动员的“动量”(后续更新程序和参考论文)
这个数学建模赛题涉及管理美加大湖流域的水资源,主要考虑如何调节水位以满足各利益相关者的需求。解决这个问题需要建立数学模型来模拟大湖流域水流网络,并通过算法来优化水位调节,同时考虑到环境条件的变化对算法的影响。具体来说,需要考虑建立大湖流域水流网络模型、水位调节算法、以及环境条件变化对算法的影响分析模型。
针对第一个问题,我们需要建立一个大湖流域水流网络模型,考虑到湖泊进出水量、温度、风向、潮汐、降水、蒸发、河流流量等因素。可以利用网络流模型或动态系统模型来描述水流网络,考虑各个湖泊和河流之间的相互作用。然后通过最优化算法来确定各湖泊的最佳水位,以满足不同利益相关者的需求。
对于第二个问题,我们需要建立水位调节算法,根据进出水量数据来调节两个控制坝的出水量。可能的方法包括使用控制论方法或优化算法,根据历史数据建立水位调节模型,并评估模型对各利益相关者水位需求的满足程度。大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
针对第三个问题,我们需要评估算法对环境条件变化的敏感性,包括降水、冬季积雪、冰堵等因素。可以利用敏感性分析方法来评估算法对这些因素的响应程度,并提出相应的调整策略。
对于第四个问题,需要对安大略湖的利益相关者和影响因素进行深入分析,了解其水位管理的特点和挑战。可以利用数据分析方法来评估不同水位调节策略对各利益相关者的影响,并提出针对性的管理建议。
赛题全文+赛题分析+解题思路,可以看我的这篇文章:
KeepLearn:【解题思路】2024年数学建模美赛MCM/ICM D题 五大湖水位控制方案研究(后续更新程序和参考论文)
这个数学建模赛题关注于极端天气事件对财产所有者和保险公司的危机。保险业在2022年的自然灾害索赔增长了115%,而且气候变化导致的极端天气事件预计会导致保险费用的快速增加。保险公司面临盈利能力下降和财产所有者承担不起保险费用的困境。解决这个问题需要建立数学模型来评估保险公司是否应该承保风险较高的地区,并为社区领导者提供保护文化遗产的决策模型。
针对第一个问题,需要建立保险承保模型,考虑极端天气事件频发地区的风险和潜在赔偿成本,以及保险公司的盈利能力和客户数量。可能的方法包括风险评估模型和保险费率模型,通过数学优化算法来确定保险公司是否应该承保某个地区的风险。
对于第二个问题,需要建立文化遗产保护模型,考虑到建筑物的文化、历史、经济和社区意义,以及地区极端天气事件的影响。可能的方法包括建筑结构风险评估模型和文化遗产保护决策模型,通过多因素评估来确定建筑物的保护措施和程度。
针对第三个问题,需要选定一个历史地标,评估其价值,并根据保险和保护模型的结果提出未来的规划、时间表和成本建议。可能的方法包括对地标价值进行综合评估,考虑保险模型和保护模型的建议,提出保护和维护计划。
赛题全文+赛题分析+解题思路,可以看我的这篇文章:
KeepLearn:【解题思路】2024年数学建模美赛MCM/ICM E题 配置可持续财产保险(后续更新程序和参考论文)
这个数学建模赛题要求设计一个为期五年的数据驱动项目,旨在显著减少非法野生动物贸易。解决问题需要选择一个客户并为其设计合适的项目,探讨项目的可行性、影响以及可能的限制条件。具体来说,需要考虑客户身份、项目可行性、数据支持、资源需求、项目影响以及项目成功概率等方面。
针对第一个问题,需要选择一个合适的客户,这个客户应具备实施所提项目的权力、资源和兴趣。需要考虑客户的职责、使命和资金能力,以确保项目的可行性。
对于第二个问题,需要解释所提项目为何适合该客户,并利用出版的文献和自己的分析研究来支持选择。通过数据分析,需要向客户证明这是一个值得实施的项目,需要提供可行性分析、市场需求分析等支持数据。
针对第三个问题,需要确定客户实施项目所需的额外权力和资源,并做出合理的假设。需要考虑客户可能面临的挑战,并提供解决方案以确保项目的顺利进行。
对于第四个问题,需要评估项目实施后对非法野生动物贸易的影响,并通过数据分析来支持结论。需要提供量化的指标来衡量项目的成功,并根据实际情况调整项目设计。
针对第五个问题,需要评估项目达成预期目标的可能性,并进行敏感性分析以确定可能的影响因素。需要提供解决方案来应对可能的风险,并保证项目的成功实施。
赛题全文+赛题分析+解题思路,可以看我的这篇文章:
KeepLearn:【解题思路】2024年数学建模美赛MCM/ICM F题 打击非法野生动植物贸易(后续更新程序和参考论文)


版权声明
本文仅代表作者观点,不代表百度立场。
本文系作者授权百度百家发表,未经许可,不得转载。












发表评论